
NLP를 위해 데이터를 수집하는데 있어 우리는 많은 데이터를 인터넷을 통해 구하게 됩니다. 그러한 데이터의 양이 적당히 적은 수준이라면 충분히 반복작업을 통해 사용자가 직접 데이터를 수집할 수 있습니다. 그러나 그 양이 방대해지는 경우 단순히 데이터 수집에만도 수많은 시간 투자가 요구됩니다.
이렇게 Web상에 존재하는 Contents를 수집하는 작업을 크롤링(crawling)이라 합니다. 본문에서는 파이썬을 통해 이러한 크롤링을 효율적으로 수행하는 방법을 소개합니다.
예시 코드는 매경스포츠(MKsport) 사이트에서 NBA를 검색한 결과의 기사 본문을 크롤링 하는 코드입니다.
오늘 예제에서는 beautifulsoup4 라이브러리와 request 라이브러리가 필요합니다.
from bs4 import BeautifulSoup as bs
import sys
import urllib.request
from urllib.parse import quote필요한 모듈을 import 시켜줍니다.
mksport 에서 NBA를 검색한 뒤 2page로 이동하면 아래와 같은 화면이 등장합니다.(사진은 페이지수를 보여드리기 위해 최하단을 캡쳐하였습니다.)

주소창을 잘 보시면 http://mksports.co.kr/search/?page=1&kwd=NBA 실제 페이지는 2page이지만 url의 경우 1로 나타나는 것을 확인할 수 있으며, 제가 검색한 NBA는 'kwd=' 뒤에 작성되는 것을 확인할 수 있습니다. 따라서 mksport의 url은 첫 페이지가 0에서 시작하고, 검색한 단어는 kwd= 다음에 등장하는 것을 알 수 있습니다.
def get_URL(keyword):
url_page_source = "http://mksports.co.kr/search/?page="
url_keyword_source = "&kwd="
URL = url_page_source + url_keyword_source + quote(keyword)
return URL따라서 url을 얻는 함수는 page를 할당해줄 부분과 검색어를 입력할 부분을 분리하여 위와 같이 정의할 수 있습니다.
여기서 quote의 경우 한글(UTF-8) 검색어를 입력하는 경우 아스키방식을 사용하는 url과 충돌이 일어나기 때문에 사용됩니다.
def get_link(page_num, URL, output_file):
#입력하는 page_num에 따라 page가 순차적으로 추가되도록 for문 생성
for i in range(page_num):
current_page = i
#URL에서 '='의 위치를 찾고 값을 가져옴
page_index = URL.index('=')
#index함수를 통해 알아낸 =의 위치를 통해 page를 삽입하여 url 완성
URL_with_page = URL[: page_index+1] + str(current_page) + URL[page_index+1 :]
source_code_from_URL = urllib.request.urlopen(URL_with_page)
soup = bs(source_code_from_URL, 'lxml', from_encoding='utf-8')
#soup내부에 <dt,class=tit>인 모든 부분을 가져와서 title에 저장
for title in soup.find_all('dt', 'tit'):
#title에서 기사로 연결되는 링크를 가진 <a>태그를 tit_link에 저장
tit_link = title.select('a')
#<a>태그 내부에는 공통 부분인 http://mksports.co.kr/search/ 이 생략되어있기 때문에 공통부분과 <a>태그를 결합
article_url = "http://mksports.co.kr/search/" + tit_link[0]['href']
print(article_url)
#본문 내용을 가져오기위한 함수와 연결
get_text(article_url, output_file)
def get_text(URL, output_file):
#get_link함수에서 생성된 aritcle_url을 URL변수로 입력받음
source_code_from_URL = urllib.request.urlopen(URL)
soup = bs(source_code_from_URL, 'lxml', from_encoding='utf-8')
#기사 내용이 <div class=read_txt>에 저장되어 있으므로 read_txt class전체를 content에 저장
content = soup.select('div.read_txt')
for text in content :
#content안에서 text형식인 모든 자료를 꺼내와 str_item에 저장
str_item = str(text.find_all(text=True))
output_file.write(str_item)검색 결과 목록에서 각 기사 제목에 연결된 링크를 찾아내어 그 링크에서 본문을 복사해오는 코드를 작성합니다.
각주의 설명을 참고하시기 바랍니다.
page_num = input('크롤링할 페이지 수를 입력해주세요.')
keyword = input('검색어를 입력해주세요.')
output_filename = input('저장할 파일이름을 적어주세요.') + '.txt'
output_file = open(output_filename, 'w')
url = get_URL(keyword)
get_link(int(page_num), url, output_file)
output_file.close()input을 이용해 크롤링을 원하는 페이지의 수와 검색어 및 저장할 파일이름을 지정해주면 아래와 같은 결과가 나타납니다.
추출된 데이터를 살펴보면 두가지 문제를 확인할 수 있습니다.
1. 기사 초두 및 마지막 부분에 광고가 함께 삽입되는 문제.
2. 본문 내에 특수문자 등 불필요한 내용이 섞여있는 문제.
원인 분석을 위해 기사에 접속하여 개발자도구를 살펴보면 특정광고가 본문 내역 안에 <a>태그로 존재함을 알 수 있고, 기사 시작 전 첫번째 태그에 광고가 있음을 알 수 있습니다.
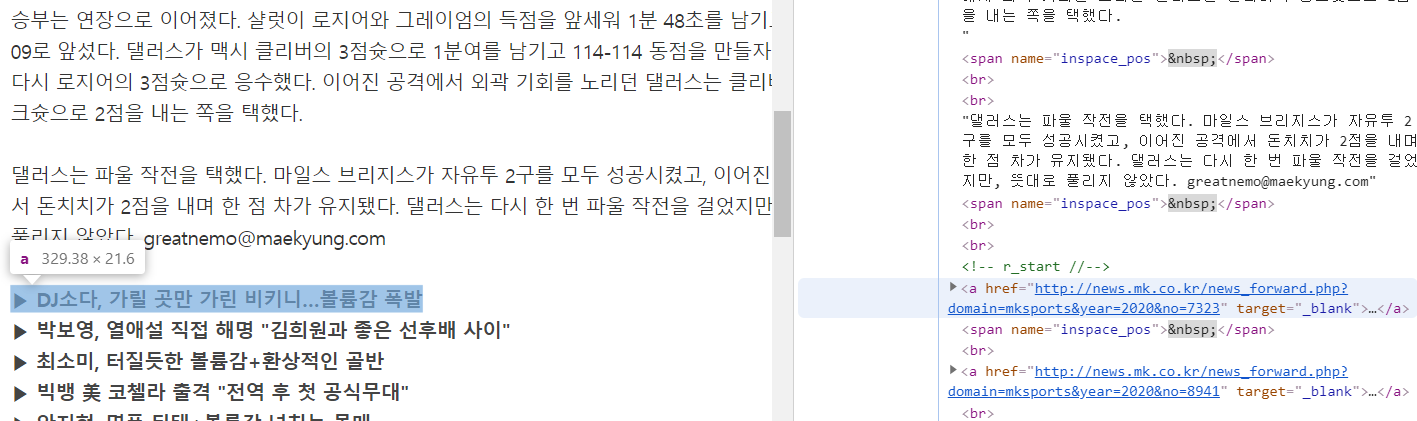
이에 대한 해결 방법은 다음 예제에서 함께 소개하도록 하겠습니다.
https://yoonpunk.tistory.com/4를 참고하였습니다.
코드전문은 https://github.com/Leo-bb/natural-language-processing를 참고하시기 바랍니다.
Leo-bb/natural-language-processing
Contribute to Leo-bb/natural-language-processing development by creating an account on GitHub.
github.com