[Python]자연어 처리를 위한 데이터 수집 웹 크롤링-2(crawling-2) list/str 자료형의 특징 및 re(정규화)
2020. 1. 6. 22:19
Data/Data Engineering
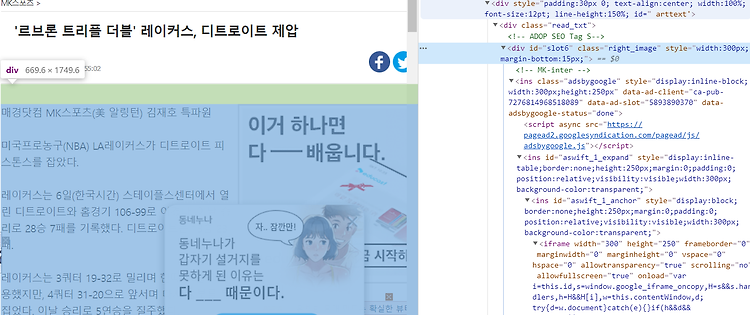
2020/01/05 - [Python 3/Natural Language Processing] - 크롤링(crawling) 크롤링(crawling) NLP를 위해 데이터를 수집하는데 있어 우리는 많은 데이터를 인터넷을 통해 구하게 됩니다. 그러한 데이터의 양이 적당히 적은 수준이라면 충분히 반복작업을 통해 사용자가 직접 데이터를 수집할 수 있습니다. 그.. leo-bb.tistory.com 읽으시기 전에 이전 글을 참고하시기 바랍니다. 이전에 추출된 데이터를 살펴보면 두가지 문제를 확인할 수 있습니다. 1. 기사 초두 및 마지막 부분에 광고 삽입. 2. 특수문자 등 불필요한 내용이 본문에 섞여있음. 기사의 html을 다시 확인해보면 본문이 나오기 전에 각종 광고 배너에 대한 class 및 태그가 먼저 등장..
[Python]자연어 처리를 위한 문장 문장 토큰화(Sentence tokenization)
2020. 1. 5. 18:58
Data/Data Engineering
[Python 3/Natural Language Processing] - 단어 토큰화(word tokenization) 단어 토큰화(word tokenization) NLP이전에 방대한 양의 문장들을 보다 쉽게 분석하고 가지고 놀기위해 어느정도 정제(cleansing)하고 정규화하는 작업이 요구됩니다. 그리고 정제와 정규화 이전에 사용자의 목적에 맞게 데이터를 토큰화하는 작업.. leo-bb.tistory.com 단어 토큰화 이전에 문서의 양이 방대해지는 경우 바로 단어 토큰화를 진행하는 것보다 문장을 토큰화해 1차적으로 정제하고 단어 토큰화를 진행하는 것도 좋은 방법입니다. 본 예제에서는 문장 단위의 토큰화 실습가 더불어 한글로 이루어진 문장의 단어 토큰화(word tokenization)을 함께 소개..
[Python]자연어 처리를 위한 단어 토큰화(word tokenization)
2020. 1. 5. 18:34
Data/Data Engineering
NLP이전에 방대한 양의 문장들을 보다 쉽게 분석하고 가지고 놀기위해 어느정도 정제(cleansing)하고 정규화하는 작업이 요구됩니다. 그리고 정제와 정규화 이전에 사용자의 목적에 맞게 데이터를 토큰화하는 작업이 요구됩니다. 오늘은 그 중 단어를 기준으로 토큰화하는 방법을 소개합니다. import nltk nltk.download('punkt') nltk.download('treebank') from nltk.tokenize import word_tokenize from nltk.tokenize import WordPunctTokenizer from nltk.tokenize import TreebankWordTokenizer tb_tokenizer=TreebankWordTokenizer() 단어 토큰화..