2020/01/05 - [Python 3/Natural Language Processing] - 크롤링(crawling)
크롤링(crawling)
NLP를 위해 데이터를 수집하는데 있어 우리는 많은 데이터를 인터넷을 통해 구하게 됩니다. 그러한 데이터의 양이 적당히 적은 수준이라면 충분히 반복작업을 통해 사용자가 직접 데이터를 수집할 수 있습니다. 그..
leo-bb.tistory.com
읽으시기 전에 이전 글을 참고하시기 바랍니다.
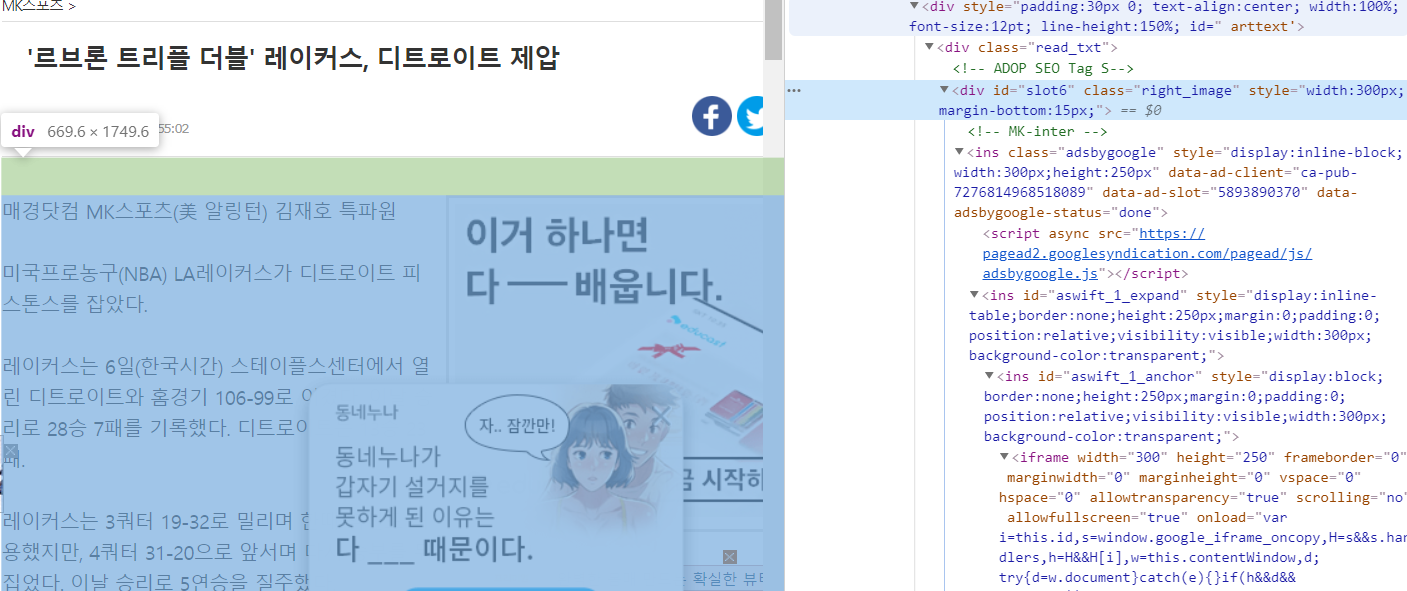
이전에 추출된 데이터를 살펴보면 두가지 문제를 확인할 수 있습니다.
1. 기사 초두 및 마지막 부분에 광고 삽입.
2. 특수문자 등 불필요한 내용이 본문에 섞여있음.
기사의 html을 다시 확인해보면 본문이 나오기 전에 각종 광고 배너에 대한 class 및 태그가 먼저 등장하는 것을 알 수 있습니다.
또한 광고와 배너에 대한 태그는 아래와 같은 태그로 끝나는 것을 확인할 수 있습니다.
| 본문 시작 전 : "'\\n'", " ' ADOP SEO Tag S\\n MK-inte\\n (adsbygoogle = window.adsbygoogle || []).push({});\\n 본문 이후 광고 시작 전 : " ' r_start //'" |

이 두가지 문제를 해결하는 방법으로 list와 str 자료형 특성과 re 정규화 모듈을 이용하는 방법을 소개합니다.
#text는 str data
def cleansing(text):
text_str2list = text.split(',')
text_start = " '\\n (adsbygoogle = window.adsbygoogle || []).push({});\\n '" #태그정보
ad_start = " ' r_start //'"
start_point = text_str2list.index(text_start) + 2
del_ad_point = text_str2list.index(ad_start)
text_without_ad = text_str2list[int(start_point):int(del_ad_point)]
text_without_html = re.sub('<.+?>', '', str(text_without_ad), 0).strip()
cleansing_txt = re.sub('[\{\}\[\]\/?.,;:|\)*~`!^\-_+<>\#$%&\\\=\(\'\"]','', text_without_html)
return cleansing_txt추출한 str 데이터 내부의 ',(쉼표)'를 기준으로 list로 변환해주면 index를 이용해 특정 부분의 추가,제거 등의 변형이 가능해집니다.
text_start = " '\\n (adsbygoogle = window.adsbygoogle || []).push({});\\n '" #태그정보
ad_start = " ' r_start //'"
start_point = text_str2list.index(text_start) + 2
del_ad_point = text_str2list.index(ad_start)
text_without_ad = text_str2list[int(start_point):int(del_ad_point)]본문의 구성은 기자 정보 - 본문 - 사진 -본문으로 구성되고 있고, 우리가 원하는 것은 순수한 본문의 내용이기 때문에 태그의 index를 기준으로 + 2 하여 저장해주고, 기사 후미의 <a>태그로 시작되는 광고 시작단은 포함되면 안되기 때문에 index를 그대로 할당합니다.
list slicing 예시 : A = [1,2,3] 인 경우 A[0:2] =1, 2 입니다.
text_without_html = re.sub('<.+?>', '', str(text_without_ad), 0).strip()
cleansing_txt = re.sub('[\{\}\[\]\/?.,;:|\)*~`!^\-_+<>\#$%&\\\=\(\'\"]','', text_without_html)아직 제거되지 않은 본문 내부의 특수문자와 각종 태그를 삭제하여 주면 전보다 훨씬 정제된 데이터를 얻을 수 있습니다.

최종적으로 클렌징 된 데이터입니다. 내용을 보시면 인코딩 과정에서 데이터가 유실되거나, 제거되지 않은 불필요한 데이터가 섞여있어 추가적인 정제가 필요해보입니다.
오늘 소개해드린 방법 외에 토큰화를 이용하는 방법도 가능하며 경우에 따라 훨씬 더 정밀한 클렌징이 가능합니다.(추가적인 예제를 추후에 게시해드리겠습니다.)
코드전문은 https://github.com/Leo-bb/natural-language-processing를 참고하시기 바랍니다.
Leo-bb/natural-language-processing
Contribute to Leo-bb/natural-language-processing development by creating an account on GitHub.
github.com