
다중 스레드를 활용한 Riss 논문 데이터 크롤러에 관한 링크입니다.
[python]파이썬 동시성/비동기 프로그래밍 5. 활용 예시 Riss Crawler 만들어서 Riss 논문 데이터 다운로
파이썬 동시성/비동기 프로그래밍 4. concurrent.futures [Python]파이썬 동시성/비동기 프로그래밍 4. concurrent.futures 파이썬 동시성/비동기 프로그래밍 3. GIL(Global interpreter Lock) [Python]파이썬 동..
leo-bb.tistory.com
현 문서와의 차이점
1. 동시성을 이용해 속도 증가
2. 쉬운 사용법과 간결함
3. 비제한적
크롤링에 관한 전반적인 방법은 이전 글을 참고해주시기 바랍니다.
1. Basic Riss crawl
어떤 목적을 가지고 연구를 진행하거나 논문을 작성할 때, 가장 먼저 진행하는 것이 관련 데이터 수집 및 자료 검색입니다. 이 경우 관련 아티클 또는 저널을 참고하는 것이 가장 유용하고, 작업물의 신뢰도를 확보할 수 있습니다.
오늘은 학술연구정보서비스인 RIss를 통해 논문을 검색하고 논문의 저자/발행일/발간지/제목/요약문을 추출하여 csv파일로 저장하는 예제를 소개합니다.
오늘 실습에 사용되는 라이브러리와 메인 실행 소스는 아래와 같으며, pandas, beautifulsoup, request, selenium, re는 필수 라이브러리입니다.
from bs4 import BeautifulSoup as bs
import urllib.request
import re
from selenium import webdriver
import pandas as pd
import datetime
import os
import getpass1.1. I. Get page url
먼저 찾고자 하는 논문의 주제와 연관된 검색어를 입력하고 크롤링을 위해 URL을 확인합니다.
예제에는 [빅데이터]와 관련된 논문을 검색하였습니다.

검색 결과를 살펴보면 구분자가 0에서 부터 10씩 증가하며, 이는 한 페이지당 10개의 논문이 표시되기 때문입니다. 따라서 가장 먼저 'iStartCount='를 기준으로 url을 구분해주어야 합니다.
def get_URL(page):
url_before_page = "http://www.riss.or.kr/search/Search.do?isDetailSearch=N&searchGubun=true&
viewYn=OP&queryText=&strQuery=%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0&exQuery=&exQueryText=&ord
er=%2FDESC&onHanja=false&strSort=RANK&p_year1=&p_year2=&iStartCount="
url_after_page = "&orderBy=&fsearchMethod=search&sflag=1&isFDetailSearch=N&pageNumber=1&resul
tKeyword=%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0&fsearchSort=&fsearchOrder=&limiterList=&limiter
ListText=&facetList=&facetListText=&fsearchDB=&icate=re_a_kor&colName=re_a_kor&pageScale=10&q
uery=%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0"
URL = url_before_page + page + url_after_page
return URL1.2. II. Get paper info link
논문의 세부정보는 논문 제목을 클릭하면 열리는 링크를 통해 확보할 수 있습니다.
따라서 링크를 얻기위해 크롬의 개발자 도구를 이용해 url을 확인합니다.
1page당 url이 10씩 이동하기 때문에 현재 페이지를 10단위로 입력하여 url을 읽어줍니다.
태그는 아래와 같은 선택자(selector)를 갖습니다.
#divContent > div.rightContent > div > div.srchResultW > div.srchResultListW > ul > li:nth-child(1) > div.cont > p.title > a
전체 li 하의 모든 a태그를 가져오기 위해 li > div.cont > p.title > a 를 사용합니다.
이 방법외에 find_all을 이용하는 방법도 있습니다.(상단 링크 예제 참고)
def get_link(csv_name, page_num):
for i in range(page_num):
current_page = i*10
URL = get_URL(str(current_page))
source_code_from_URL = urllib.request.urlopen(URL)
soup = bs(source_code_from_URL, 'lxml', from_encoding='utf-8')
for j in range(10):
paper_link = soup.select('li > div.cont > p.title > a')[j]['href']
paper_url = "http://riss.or.kr" + paper_link
reference_data = get_reference(paper_url)
save_csv(csv_name, reference_data)1.3. III. Get paper info
이를 통해 얻은 각 논문별 url을 얻어오면 get_reference 함수를 통해 정보를 얻고 save_csv함수를 통해 최종적으로 csv파일을 저장하게 됩니다.

세부 정보가 기록된 페이지는 스크립트가 실행되기 때문에 단순히 requests.get으로는 필요한 정보를 가져올 수 없습니다. 따라서 셀레니움을 이용하여 실제로 웹사이트를 열고, 스크립트가 실행되도록 한 뒤 크롤링을 시도해야 합니다.(또는 requests.session을 활용할 수 있습니다.)
셀레니움의 웹 드라이버를 이용하여(예제는 크롬을 사용하였습니다.) 웹사이트를 열고 page source를 가져와 beautifulsoup으로 가져옵니다.
제목에 대한 정보는 #soptionview > div > div.thesisInfo > div.thesisInfoTop > h3 내부에 들어있고, 논문의 세부 정보는 #soptionview > div > div.thesisInfo > div.infoDetail.on > div.infoDetailL > ul > li > div > p 내부에 존재합니다. 따라서 해당 논문의 정보를 가져오기 위해 각 태그에 개별적으로 접근해야 합니다.
최종적으로 논문의 제목, 저자, 저서, 키워드, 링크를 얻고 pandas의 데이터 프레임 형태로 저장해 줍니다.
def get_reference(URL):
driver_path = os.path.join(ROOT_PATH, "chromedriver")
driver = webdriver.Chrome(driver_path, options=webdriver.ChromeOptions().add_argument("headless"))
driver.get(URL)
html = driver.page_source
soup = bs(html, "html.parser")
title = soup.find("h3", "title")
title_txt = title.get_text("", strip=True).split("=")
title_kor = re.sub("\n\b", "", str(title_txt[0]).strip())
title_eng = str(title_txt[1]).strip()
txt_box = []
for text in soup.find_all("div", "text"):
txt = text.get_text("", strip=True)
txt_box.append(txt)
txt_kor = txt_box[1]
txt_eng = txt_box[3]
detail_box = []
detail_info = soup.select(
"#soptionview > div > div.thesisInfo > div.infoDetail.on > div.infoDetailL > ul > li > div > p"
)
for detail in detail_info:
detail_content = detail.get_text("", strip=True)
detail_wrap = []
detail_wrap.append(detail_content)
detail_box.append(detail_wrap)
author = ",".join(detail_box[0])
book = (
"".join(detail_box[2] + detail_box[3]).replace("\n", "").replace("\t", "").replace(" ", "")
+ " p."
+ "".join(detail_box[-2])
)
keyword = ",".join(detail_box[6])
reference_data = pd.DataFrame(
{
"저자": [author],
"국문 제목": [title_kor],
"영문 제목": [title_eng],
"수록지": [book],
"핵심어": [keyword],
"국문 요약": [txt_kor],
"영문 요약": [txt_eng],
"링크": [URL],
}
)
driver.close()
return reference_dataIV. save csv
save_csv함수는 경로와 데이터 프레임을 인자로 받습니다.
사용자가 입력한 파일 이름을 통해 경로를 생성하게 되며, os.isfile을 통해 해당 파일의 존재 여부를 파악한 뒤, 파일이 존재하지 않으면 새로 쓰기를, 존재한다면 내용 추가를 실행합니다.
이때 주의하실 점은 path는 기본적으로 '/'로 구분되지만 pandas의 to_csv의 경우 경로를'\\'로 구분하기 때문에 replace를 통해 수정해주어야 합니다.
최종적으로 파일을 실행시키면 input을 통해 저장할 파일 이름과 크롤링할 페이지 수를 얻게 되며, 결과는 아래와 같이 저장되게 됩니다.
def save_csv(csv_path, data):
csv = csv_path.replace("/","\\")
if os.path.isfile(csv_path):
data.to_csv(csv, mode='a', header = False, index=False)
else:
data.to_csv(csv, mode='w',header = True, index=False)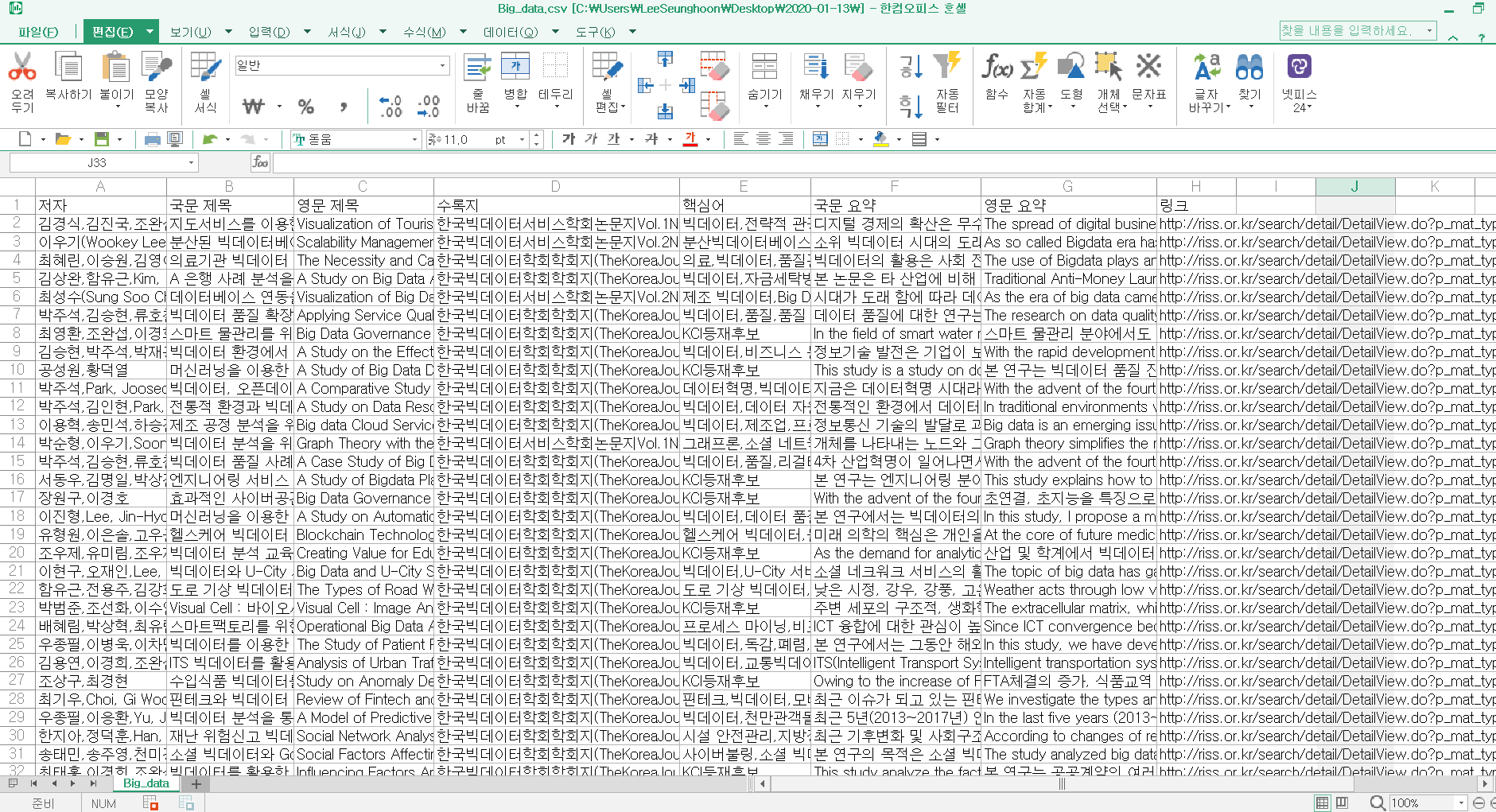
위 함수들을 모두 사용한 전문
from bs4 import BeautifulSoup as bs
import urllib.request
import re
from selenium import webdriver
import pandas as pd
import datetime
import os
import getpass
# RISS에 논문을 검색하여 제목/저자/요약본문/링크를 csv 파일로 저장
def get_URL(page):
url_before_page = "http://www.riss.or.kr/search/Search.do?isDetailSearch=N&searchGubun=true&viewYn=OP&queryText=&strQuery=%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0&exQuery=&exQueryText=&order=%2FDESC&onHanja=false&strSort=RANK&p_year1=&p_year2=&iStartCount="
url_after_page = "&orderBy=&fsearchMethod=search&sflag=1&isFDetailSearch=N&pageNumber=1&resultKeyword=%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0&fsearchSort=&fsearchOrder=&limiterList=&limiterListText=&facetList=&facetListText=&fsearchDB=&icate=re_a_kor&colName=re_a_kor&pageScale=10&query=%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0"
URL = url_before_page + page + url_after_page
return URL
def get_link(csv_name, page_num):
for i in range(page_num):
current_page = i * 10
URL = get_URL(str(current_page))
source_code_from_URL = urllib.request.urlopen(URL)
soup = bs(source_code_from_URL, "lxml", from_encoding="utf-8")
for j in range(10):
paper_link = soup.select("li > div.cont > p.title > a")[j]["href"]
paper_url = "http://riss.or.kr" + paper_link
re = get_reference(paper_url)
save_csv(csv_name, re)
def get_reference(URL):
driver = webdriver.Chrome("your/chrome/driver/path")
driver.get(URL)
html = driver.page_source
soup = bs(html, "html.parser")
title = soup.find("h3", "title")
title_txt = title.get_text("", strip=True).split("=")
title_kor = re.sub("\n\b", "", str(title_txt[0]).strip())
title_eng = str(title_txt[1]).strip()
txt_box = []
for text in soup.find_all("div", "text"):
txt = text.get_text("", strip=True)
txt_box.append(txt)
txt_kor = txt_box[1]
txt_eng = txt_box[3]
detail_box = []
detail_info = soup.select(
"#soptionview > div > div.thesisInfo > div.infoDetail.on > div.infoDetailL > ul > li > div > p"
)
for detail in detail_info:
detail_content = detail.get_text("", strip=True)
detail_wrap = []
detail_wrap.append(detail_content)
detail_box.append(detail_wrap)
author = ",".join(detail_box[0])
book = (
"".join(detail_box[2] + detail_box[3]).replace("\n", "").replace("\t", "").replace(" ", "")
+ " p."
+ "".join(detail_box[-2])
)
keyword = ",".join(detail_box[6])
reference_data = pd.DataFrame(
{
"저자": [author],
"국문 제목": [title_kor],
"영문 제목": [title_eng],
"수록지": [book],
"핵심어": [keyword],
"국문 요약": [txt_kor],
"영문 요약": [txt_eng],
"링크": [URL],
}
)
driver.close()
return reference_data
def save_csv(csv_path, data):
csv = csv_path.replace("/", "\\")
if os.path.isfile(csv_path):
data.to_csv(csv, mode="a", header=False, index=False)
else:
data.to_csv(csv, mode="w", header=True, index=False)
def make_folder(folder_name):
if not os.path.isdir(folder_name):
os.mkdir(folder_name)
if __name__ == "__main__":
now = datetime.datetime.now().strftime("%Y-%m-%d")
user_name = getpass.getuser()
folder_root = "your path"
path = folder_root + now
make_folder(path)
filename = input("저장할 csv 이름을 입력해주세요")
csv_path = path + "/" + filename + ".csv"
page_num = input("크롤링할 페이지 수를 입력해주세요.")
get_link(csv_path, int(page_num))