
[Python]자연어 처리를 위한 데이터 수집 웹 크롤링-1(crawling)
2020. 1. 5. 20:34
Data/Data Engineering
NLP를 위해 데이터를 수집하는데 있어 우리는 많은 데이터를 인터넷을 통해 구하게 됩니다. 그러한 데이터의 양이 적당히 적은 수준이라면 충분히 반복작업을 통해 사용자가 직접 데이터를 수집할 수 있습니다. 그러나 그 양이 방대해지는 경우 단순히 데이터 수집에만도 수많은 시간 투자가 요구됩니다. 이렇게 Web상에 존재하는 Contents를 수집하는 작업을 크롤링(crawling)이라 합니다. 본문에서는 파이썬을 통해 이러한 크롤링을 효율적으로 수행하는 방법을 소개합니다. 예시 코드는 매경스포츠(MKsport) 사이트에서 NBA를 검색한 결과의 기사 본문을 크롤링 하는 코드입니다. 오늘 예제에서는 beautifulsoup4 라이브러리와 request 라이브러리가 필요합니다. from bs4 import Bea..
[Python]자연어 처리를 위한 정규화 방법 - 어간추출(stemming)
2020. 1. 5. 19:49
Data/Data Engineering
토큰화와 클렌징을 통해 어느 정도 데이터를 분류하였다면, 정규화를 통해 전체 데이터의 수를 줄일 수 있습니다. NLP에서 정규화를 설명할 때 가장 자주 등장하는 예시가 be 동사입니다. be동사는 is, are, am 등 사용할 때는 다양하게 나타나지만 실질적인 의미는 'be'로 볼 수 있습니다. 따라서 주어진 데이터 내에서 be동사로 표현되는 모든 단어를 개별 데이터로 보는 것이 아닌 be라는 1개의 데이터로 취급하게 되면 전체 데이터의 총량이 감소하게되며 이러한 작업을 정규화라 합니다. 본문에서는 porter알고리즘과 lancaster알고리즘을 통해 어간을 추출하는 방법을 소개합니다. 다만 어간 추출 자체가 정교한 작업은 아닙니다. 설정되어 있는 규칙에 의해 단어를 분리하기 때문에 분리된 단어는 실제..
[Python]자연어 처리를 위한 불용어 제거방법(stopword processing)
2020. 1. 5. 19:18
Data/Data Engineering
불용어 처리 I. 불용어 불용어란 데이터 셋에 자주 등장하지만 분석에 큰 의미는 갖지 않는 단어를 말합니다. 불용어가 다수 포함되어 있을수록 효율 감소, 처리시간 증가 등 악영향이 발생합니다. 불용어 처리를 위해 영문의 경우 대표적인 불용어를 nltk모듈에서 제공하고 있으며, 한국어의 경우 따로 제공되는 리스트는 없으나 아래 링크를 활용할 수 있습니다. 대체적으로 불용어는 데이터를 분석하는 연구진에 의해 임의로 설정하는 경우가 많습니다. 한국어 불용어 리스트 100개 : https://bab2min.tistory.com/544 II. 기초 불용어 처리 from nltk.corpus import stopwords from nltk.tokenize import word_tokenize word = " 불용어..
[Python]자연어 처리를 위한 문장 문장 토큰화(Sentence tokenization)
2020. 1. 5. 18:58
Data/Data Engineering
[Python 3/Natural Language Processing] - 단어 토큰화(word tokenization) 단어 토큰화(word tokenization) NLP이전에 방대한 양의 문장들을 보다 쉽게 분석하고 가지고 놀기위해 어느정도 정제(cleansing)하고 정규화하는 작업이 요구됩니다. 그리고 정제와 정규화 이전에 사용자의 목적에 맞게 데이터를 토큰화하는 작업.. leo-bb.tistory.com 단어 토큰화 이전에 문서의 양이 방대해지는 경우 바로 단어 토큰화를 진행하는 것보다 문장을 토큰화해 1차적으로 정제하고 단어 토큰화를 진행하는 것도 좋은 방법입니다. 본 예제에서는 문장 단위의 토큰화 실습가 더불어 한글로 이루어진 문장의 단어 토큰화(word tokenization)을 함께 소개..
[Python]자연어 처리를 위한 단어 토큰화(word tokenization)
2020. 1. 5. 18:34
Data/Data Engineering
NLP이전에 방대한 양의 문장들을 보다 쉽게 분석하고 가지고 놀기위해 어느정도 정제(cleansing)하고 정규화하는 작업이 요구됩니다. 그리고 정제와 정규화 이전에 사용자의 목적에 맞게 데이터를 토큰화하는 작업이 요구됩니다. 오늘은 그 중 단어를 기준으로 토큰화하는 방법을 소개합니다. import nltk nltk.download('punkt') nltk.download('treebank') from nltk.tokenize import word_tokenize from nltk.tokenize import WordPunctTokenizer from nltk.tokenize import TreebankWordTokenizer tb_tokenizer=TreebankWordTokenizer() 단어 토큰화..
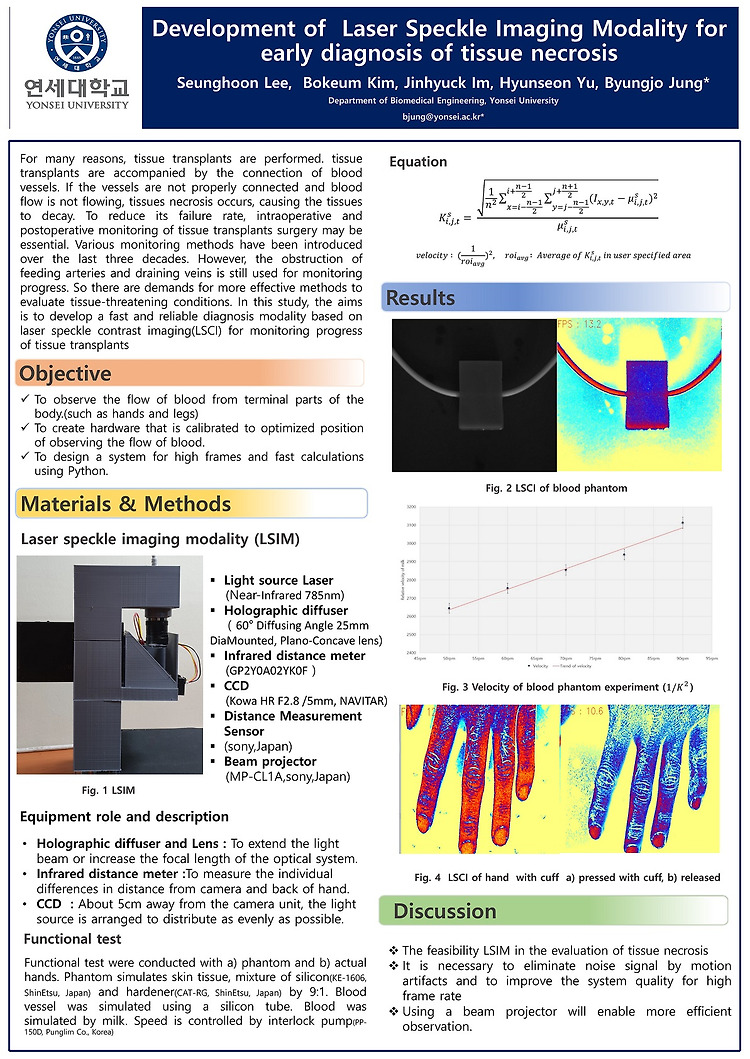
LSCI(Laser Spekcle Contrast imaging)을 이용한 프로젝트
2020. 1. 2. 18:27
Project/Laser Speckle Image system
55회 대한의용생체공학회 추계학술대회 출연 연구 자료입니다.