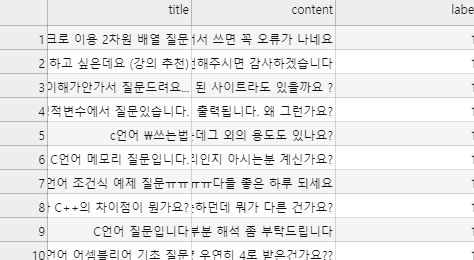
[Python/NLP]문서 간 코사인 유사도에 기반한 '유사 게시물 추천 시스템' 만들기(pandas, scikit-learn, tf-idf)
2020. 2. 5. 23:40
Data/ML
2020/01/11 - [Python 3/Natural Language Processing] - [python/NLP]웹 크롤링(crawling) 심화 - Riss 논문 검색 데이터를 csv파일로 저장하기 [python/NLP]웹 크롤링(crawling) 심화 - Riss 논문 검색 데이터를 csv파일로 저장하기 [Python]자연어 처리를 위한 데이터 수집 웹 크롤링-2(crawling-2) list/str 자료형의 특징 및 re(정규화) 2020/01/05 - [Python 3/Natural Language Processing] - 크롤링(crawling) 크롤링(crawling) NLP를 위해.. leo-bb.tistory.com 여태까지 다양한 사이트의 메타 데이터 중 필요한 데이터만 얻어오는 크..
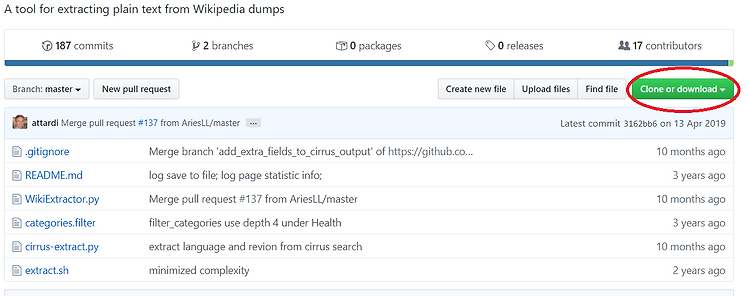
[Python/NLP]WikiExtractor를 이용한 위키덤프(Wiki dump)파싱 for Mac/window
2020. 1. 23. 20:32
Data/Data Engineering
기초적인 자연어 처리를 위해 데이터를 수집하는 경우 신문기사와 더불어 위키 덤프(wiki dump)를 많이 활용합니다. 오늘은 위키덤프를 다운로드 받고 파싱하여 txt형태로 저장하는 방법을 소개합니다. 1. 한글 위키 덤프 파일 다운로드 아래 링크를 통해 내용만 담긴 가장 최신 데이터를 받으실 수 있습니다. http://dumps.wikimedia.org/kowiki/latest/kowiki-latest-pages-articles.xml.bz2 다른 한글 위키 덤프 파일의 경우 아래 링크에서 받으실 수 있습니다. https://ko.wikipedia.org/wiki/%EC%9C%84%ED%82%A4%EB%B0%B1%EA%B3%BC:%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9..

[python]웹 크롤링(crawling) - Riss 논문 검색 데이터를 csv파일로 저장하기
2020. 1. 11. 14:35
Data/Data Engineering
다중 스레드를 활용한 Riss 논문 데이터 크롤러에 관한 링크입니다. [python]파이썬 동시성/비동기 프로그래밍 5. 활용 예시 Riss Crawler 만들어서 Riss 논문 데이터 다운로 파이썬 동시성/비동기 프로그래밍 4. concurrent.futures [Python]파이썬 동시성/비동기 프로그래밍 4. concurrent.futures 파이썬 동시성/비동기 프로그래밍 3. GIL(Global interpreter Lock) [Python]파이썬 동.. leo-bb.tistory.com 현 문서와의 차이점 1. 동시성을 이용해 속도 증가 2. 쉬운 사용법과 간결함 3. 비제한적 크롤링에 관한 전반적인 방법은 이전 글을 참고해주시기 바랍니다. Basic Riss crawl 어떤 목적을 가지고 연..
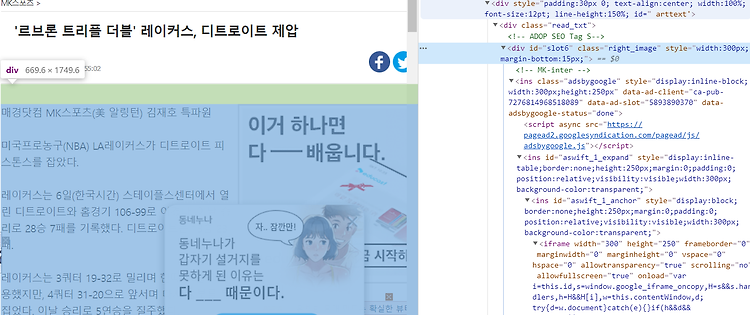
[Python]자연어 처리를 위한 데이터 수집 웹 크롤링-2(crawling-2) list/str 자료형의 특징 및 re(정규화)
2020. 1. 6. 22:19
Data/Data Engineering
2020/01/05 - [Python 3/Natural Language Processing] - 크롤링(crawling) 크롤링(crawling) NLP를 위해 데이터를 수집하는데 있어 우리는 많은 데이터를 인터넷을 통해 구하게 됩니다. 그러한 데이터의 양이 적당히 적은 수준이라면 충분히 반복작업을 통해 사용자가 직접 데이터를 수집할 수 있습니다. 그.. leo-bb.tistory.com 읽으시기 전에 이전 글을 참고하시기 바랍니다. 이전에 추출된 데이터를 살펴보면 두가지 문제를 확인할 수 있습니다. 1. 기사 초두 및 마지막 부분에 광고 삽입. 2. 특수문자 등 불필요한 내용이 본문에 섞여있음. 기사의 html을 다시 확인해보면 본문이 나오기 전에 각종 광고 배너에 대한 class 및 태그가 먼저 등장..

[Python]자연어 처리를 위한 데이터 수집 웹 크롤링-1(crawling)
2020. 1. 5. 20:34
Data/Data Engineering
NLP를 위해 데이터를 수집하는데 있어 우리는 많은 데이터를 인터넷을 통해 구하게 됩니다. 그러한 데이터의 양이 적당히 적은 수준이라면 충분히 반복작업을 통해 사용자가 직접 데이터를 수집할 수 있습니다. 그러나 그 양이 방대해지는 경우 단순히 데이터 수집에만도 수많은 시간 투자가 요구됩니다. 이렇게 Web상에 존재하는 Contents를 수집하는 작업을 크롤링(crawling)이라 합니다. 본문에서는 파이썬을 통해 이러한 크롤링을 효율적으로 수행하는 방법을 소개합니다. 예시 코드는 매경스포츠(MKsport) 사이트에서 NBA를 검색한 결과의 기사 본문을 크롤링 하는 코드입니다. 오늘 예제에서는 beautifulsoup4 라이브러리와 request 라이브러리가 필요합니다. from bs4 import Bea..
[Python]자연어 처리를 위한 불용어 제거방법(stopword processing)
2020. 1. 5. 19:18
Data/Data Engineering
불용어 처리 I. 불용어 불용어란 데이터 셋에 자주 등장하지만 분석에 큰 의미는 갖지 않는 단어를 말합니다. 불용어가 다수 포함되어 있을수록 효율 감소, 처리시간 증가 등 악영향이 발생합니다. 불용어 처리를 위해 영문의 경우 대표적인 불용어를 nltk모듈에서 제공하고 있으며, 한국어의 경우 따로 제공되는 리스트는 없으나 아래 링크를 활용할 수 있습니다. 대체적으로 불용어는 데이터를 분석하는 연구진에 의해 임의로 설정하는 경우가 많습니다. 한국어 불용어 리스트 100개 : https://bab2min.tistory.com/544 II. 기초 불용어 처리 from nltk.corpus import stopwords from nltk.tokenize import word_tokenize word = " 불용어..
[Python]자연어 처리를 위한 문장 문장 토큰화(Sentence tokenization)
2020. 1. 5. 18:58
Data/Data Engineering
[Python 3/Natural Language Processing] - 단어 토큰화(word tokenization) 단어 토큰화(word tokenization) NLP이전에 방대한 양의 문장들을 보다 쉽게 분석하고 가지고 놀기위해 어느정도 정제(cleansing)하고 정규화하는 작업이 요구됩니다. 그리고 정제와 정규화 이전에 사용자의 목적에 맞게 데이터를 토큰화하는 작업.. leo-bb.tistory.com 단어 토큰화 이전에 문서의 양이 방대해지는 경우 바로 단어 토큰화를 진행하는 것보다 문장을 토큰화해 1차적으로 정제하고 단어 토큰화를 진행하는 것도 좋은 방법입니다. 본 예제에서는 문장 단위의 토큰화 실습가 더불어 한글로 이루어진 문장의 단어 토큰화(word tokenization)을 함께 소개..